计费说明
万模API 以令牌、模型价格、分组策略和动态计费规则为基础进行按量计费。不同模型、不同上游、不同上下文长度和不同服务档位,价格可能不同。
一句话理解
你可以把一次调用的费用理解为:
如果模型启用了动态计费,还会根据上下文长度、服务层级、请求参数或时间规则进入不同价格档位。
核心概念
示例:普通文本对话
假设某模型配置为:
一次请求消耗:
则费用约为:
实际展示会按系统货币设置和汇率转换。
动态计费是什么
部分模型不是固定单价,而是按条件进入不同档位。例如:
动态计费常见于长上下文模型、不同服务层级模型和多模态模型。
分组会影响什么
令牌所属分组可能影响:
- 可用模型列表。
- 模型价格倍率。
- 请求限流和并发。
- 渠道优先级。
- 是否允许某些高级模型。
如果你看到“模型不存在”,但别人能用同一个模型,优先检查令牌分组。
在哪里看实际账单
- 打开控制台。
- 进入调用日志或消费记录。
- 查看模型、输入输出用量、扣费、错误信息。
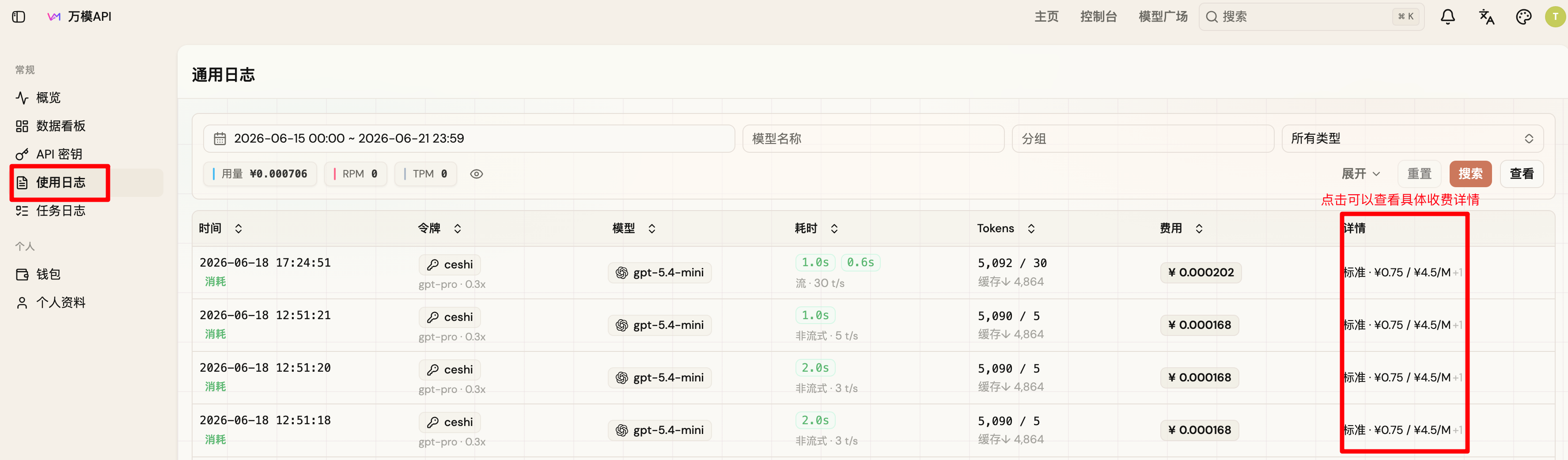
常见问题
为什么同一个模型每次扣费不同?
常见原因是输入长度、输出长度、是否命中缓存、是否进入长上下文档位不同。
为什么客户端显示的 token 和账单不同?
不同客户端的 token 估算方式可能不同。最终以网关实际记录和上游返回用量为准。
请求失败会扣费吗?
通常未成功进入模型推理的请求不会按正常完成请求计费。若上游已产生用量,具体以调用日志为准。
价格表在哪里?
实时价格以主站价格页和控制台配置为准。